‘Google Translate’-like program for Akkadian cuneiform will enable tens of thousands of digitized but unread tablets to be translated to English. Accuracy is debatable
By Melanie Lidman Today, 9:57 am

Cuneiform is the oldest known form of writing, but it is so difficult to read that only a few hundred experts around the world can decode the clay tablets filled with wedge-shaped symbols. Now, a team of archaeologists and computer scientists from Israel has created an AI-powered translation program for ancient Akkadian cuneiform, allowing tens of thousands of already digitized tablets to be translated into English instantaneously.
Globally, libraries, museums, and universities have more than half a million clay tablets inscribed with cuneiform. But the sheer number of texts, and the tiny number of Akkadian readers — a language no one has spoken or written for 2,000 years — means just a small fraction of these tablets have been translated.
A new Google Translate-type program may allow armchair archaeologists to try their hand at cuneiform interpretation.
“What’s so amazing about it is that I don’t need to understand Akkadian at all to translate [a tablet] and get what’s behind the cuneiform,” said Gai Gutherz, a computer scientist who was part of the team that developed the program. “I can just use the algorithm to understand and discover what the past has to say.”
The project began as a thesis project for Gutherz’s masters degree at Tel Aviv University. In May, the team published a research paper in the peer-reviewed PNAS Nexus, from the Oxford University Press, describing its neural machine translation from Akkadian to English.
Neural machine translation, also used by Google Translate, Baidu translate, and other translation engines, works by converting words into a string of numbers, and uses a complex mathematical formula, called a neural network, to output a sentence in another language in a more accurate and natural sentence construction than translating word-for-word.

Akkadian was written and spoken in Mesopotamia and the Middle East from around 3,000 BCE to 100 CE. It was the lingua franca of the time, allowing people from different regions to communicate. The language split into Assyrian Akkadian, and Babylonian Akkadian around the year 2000 BCE. Starting around 600 BCE, Aramaic slowly began to replace Akkadian, until it became much more widely spoken.
Akkadian and its predecessor, Sumerian, were written using cuneiform, in which a sharpened reed creates wedge-shaped markings on a wet piece of clay. The Akkadian and Sumerian cuneiform are the earliest written languages ever discovered, though there are vastly more Akkadian than Sumerian texts available.
Advertisement
Translating all the tablets that remain untranslated could expose us to the first days of history
“Translating all the tablets that remain untranslated could expose us to the first days of history, to the civilization of those people, what they believed in, what they were talking about, what they were documenting,” said Gutherz.
Some of the translated tablets have information that is still relevant today. “If he cleans his garments, his days will be long,” according to one Akkadian scribe more than 3,000 years ago.

The team is also sharing its opensource research online, in the hope that other experts can create translation programs for other ancient or dead languages, Guetherz said.
Lost in translation?
Translation is an art form, so it can be difficult to measure numerically what constitutes a “good” translation, Gutherz said. In order to rate the translations, the researchers used the Best Bilingual Evaluation Understudy 4 (BLEU4), an evaluation tool developed in the early 2000s to automatically measure the accuracy of machine-created translations.
According to the study, the neural machine translation provided a BLEU4 score of 36.52 for cuneiform to English, and a score of 37.47 for transliterated cuneiform to English. BLEU4 scores are from 0 to 100, with 0 being the lowest and 100 being a perfect translation, which even a human translator could not achieve. Around 37 is considered fairly good for an early-stage translation model, explained Gutherz.
Advertisement
Gutherz said that Google Translate, a privately-funded commercial tool that has been in existence for over a decade, would get a BLEU4 score of about 60 translating from Spanish to English.
“One of the main achievements in the research is we showed that it’s possible to get a high-quality translation going directly from cuneiform to English,” said Gutherz, who was previously a software engineer for Google and is now starting an AI business involving different technology from this project. The current time-consuming research process usually requires experts to translate the cuneiform first to the Latin transliteration, and then largely to English.
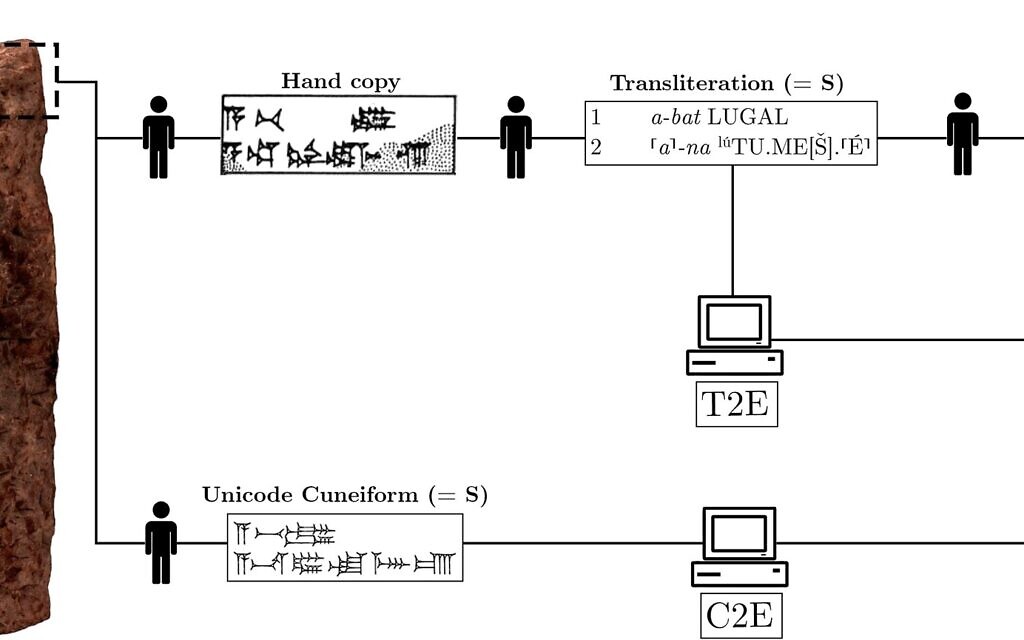
In 2020, Gutherz, archaeologist Prof. Shai Gordin of Ariel University, and others published a paper about using AI to translate Akkadian cuneiform to a transliterated Latin script. The transliterated script reads as a nonsensical collection of letters and numbers to the untrained eye, but is a common “language” that allows archaeologists and researchers to study and discuss cuneiform across the world.
In the 2020 paper, the team was able to use AI to achieve 97 percent accuracy from Akkadian cuneiform to transliterated Latin script. This is a much simpler process since it works by translating the cuneiform symbols to a single word, and keeping the words in the same order that they were found.
Translating Akkadian to English or transliterated script to English is a much more complicated process because it requires the computer to string together full phrases or sentences that make sense in English, which is written in a different syntactical order.
Some translations were very good… and some were total ‘hallucinations’
Gutherz said that despite the complexity, the AI translations performed better than expected, though the program is still in the early stages and far from precise. Predictably, the AI had a higher level of accuracy for formulaic texts, such as royal decrees or divinations, which follow a certain pattern. More literary and poetic texts, such as letters from priests or treaties, had a higher incidence of “hallucinations,” an AI term meaning that the machine produced a result that is completely unrelated to the text provided.

One of the things that most surprised the researchers is that the translations captured the style or rhythm of a certain genre so that they could determine — simply based on the style of the translation — if the text was a formulaic legal document, astrological report, or scholarly letter.
Advertisement
“Some translations were very good, some were near the point, where you could start from it, but you would have to make it more accurate manually, and some were total hallucinations,” said Gutherz. “This is the first step for an automatic translation for Akkadian and ancient languages, and I really hope more research will be done in this area and translations will get better and have higher accuracy.”
Just like Google Translate
The biggest challenge for training the AI model was the limited amount of material — images of tablets and translated tablets — that the team had available to train the AI model. Even the largest online databases of Akkadian tablets have only tens of thousands of entries.
“The amount of data you train on is correlative to how well you can perform, and the more data you have, the better your models will be,” said Gutherz. “ChatGPT works so well because they managed to train it on basically the entire internet. For us, the main task at the beginning was to gather all the possible translations we could get, to generate as many examples as possible.”

The team drew their samples from ORACC, the Open Richly Annotated Cuneiform Corpus, an online database from the University of Pennsylvania. For the data they were able to scan, the researchers used 90% of the material for training (50,544 sentences), 5% for validation (2,808 sentences), and 5% for testing (2,808 sentences).
During the 3,000 years that Akkadian was used, there are massive variances. Written Akkadian from 1,000 years apart can have completely different cuneiform symbols, and there were differences in dialects, which add to the complexity.
Gutherz said he decided to take on ancient languages for his final project in natural language processing (NLP), after archaeologist Prof. Shai Gordin, a senior lecturer in Assyriology and Digital Humanities at Ariel University, made a presentation to his NLP class.
Not many researchers are trying to use modern computer science methods to try to work on ancient languages
Advertisement
“I’m interested in history, I think it has a lot to teach us,” said Gutherz. “I realize that not many researchers are trying to use modern computer science methods to try to work on ancient languages. It’s a field that I felt I could contribute to because it’s not in the spotlight… not many people are working on it.”
Just click ‘translate’
An early demo version of the translation project from cuneiform to transliteration is available online to the public on a portal called The Babylon Engine. The research and source code for the current project can be found on GitHub on Akkademia and the Colaboratory.
Not all Akkadian experts are lining up to use the new technology, though.
“I’m an old school philologist who’s sitting at a table, looking at the tablets and reading them as humans used to do for thousands of years,” said Prof. Nathan Wasserman, a professor of Assyriology at the Institute of Archaeology at the Hebrew University of Jerusalem. He looked into the AI translation opportunities in the paper, but is not convinced that they would be useful for him.
“We’re post-ChatGPT and we’re in a different world now, so if I say, ‘It won’t work,’ that makes me look stupid,” Wasserman said. “Of course, it will work, I didn’t land from the moon yesterday. But for deeper and less formulaic texts, this is still very far from being useful.”

Wasserman’s area of expertise is the most complicated and poetic Akkadian texts, including hymns, prayers, and myths, often found on tablets that are in the worst condition and exceptionally difficult to read. His work is not just about translating, but about understanding the context within Akkadian culture and literature, he said. And he is interested in watching the way this technology develops, even if he is not rushing to use it now.
“I’m old enough to remember the start of Google Translate, and it was a joke, but now you can do large amounts of texts and get a decent result, plus or minus,” he said. “But what happens if you put Hamlet into Google Translate, will you get a decent translation of Shakespeare’s Hamlet?”
Wasserman said he thinks that AI can be most useful to scan large bodies of digitized tablets and try to find connections. For example, the names of a certain priest or king could pop up on two totally unrelated tablets, maybe even ones that were found in different locations and are housed at different libraries and could lead to new understandings. He is also curious about using the program to track statistics about different word usage, including the chronological or geographic distribution of certain words.

Wasserman counts himself among the “old school” researchers, but he is no enemy to using technology for ancient languages. Wasserman was part of the team that developed SEAL, Sources of Early Akkadian Literature. The online database, hosted by Hebrew University, was one of the pioneering digitization projects of Akkadian cuneiform tablets when it started in 2010. Newly digitized tablets are still uploaded on a regular basis, and the site today remains one of the largest deposits of Akkadian literary works from 3000-1000 BCE.
“I’m not worried [about AI], I’m curious, it’s a brave new world and I’m curious to see what will happen,” he said. “It’s not like I’m working in a bank, and worried I’ll be sent home because a machine will do my work.”
“When you have a text, even when you have the words correct, it doesn’t mean you understand what’s there. For that, you still need the human mind,” he said. “I’m not afraid of [the AI], but also, we should not be totally infatuated with it. It should be evaluated for what it can do for us, and for what it cannot.”
Content retrieved from: https://www.timesofisrael.com/groundbreaking-ai-project-translates-5000-year-old-cuneiform-at-push-of-a-button/?utm_source=dlvr.it&utm_medium=twitter.